Dataset Download
The table below provides links to each task within the dataset. Please be aware that these files are quite large and may require significant download time. If you need alternative download options, please contact the authors directly. To ensure the integrity of the downloaded files, it is recommended to verify the checksums using SHA256 (Download 128x128, Download 256x256) or SHA512 (Download 128x128, Download 256x256) . Here are the instructions for checking the checksum and unpacking the squashfs files:
- Download the file and its corresponding checksum file.
- Run the following command to check the SHA256 checksum:
sha256sum -c SHA256SUMS - To work with the squashfs file, you will need
unsquashfs. If you don't have it installed, you can install it on Linux using:sudo apt install squashfs-tools - You can mount the squashfs file without unpacking it once
unsquashfsis installed. To do this, create a mount point and then mount the file:sudo mkdir /mnt/rlbench_data
mount filename.squashfs /mnt/rlbench_data -t squashfs -o loop - Alternatively, run the following command to unpack the file:
unsquashfs filename.squashfs - The contents will be extracted to a directory named
squashfs-rootby default. You can specify a different directory using the-doption:unsquashfs -d /mnt/rlbench_data filename.squashfs
If you encounter any discrepancies or have questions, please do not hesitate to reach out to the authors for assistance.
Abstract
Bimanual manipulation is challenging due to precise spatial and temporal coordination required between two arms. While there exist several real-world bimanual systems, there is a lack of simulated benchmarks with a large task diversity for systematically studying bimanual capabilities across a wide range of table- top tasks. This paper addresses the gap by extending RLBench to bimanual manipulation. We open-source our code and benchmark, which comprises 13 new tasks with 23 unique task variations, each requiring a high degree of coordination and adaptability. To initiate the benchmark, we extended several state-of-the-art methods to bimanual manipulation and also present a language-conditioned behavioral cloning agent – PerAct2, an extension of the PerAct framework. This method enables the learning and execution of bimanual 6-DoF manipulation tasks. Our novel network architecture efficiently integrates language processing with action prediction, allowing robots to understand and perform complex bimanual tasks in response to user-specified goals.
Benchmark
Benchmarking Bimanual Robotic Manipulation Tasks
To benchmark, we extend RLBench to the complex bimanual case by adding functionality and tasks for
bimanual manipulation
RLBench is a robot learning benchmark suite consisting of more than 100 tasks to facilitate robot
learning, which is widely used in the community. Among task diversity other key properties include
reproducibility or the ability to adapt to different learning strategies.
We extend RLBench to bimanual manipulation, while keeping the functionality and its key properties. This
allows us to quantify the success of our method and to compare it against other baselines. Compared to
unimanual manipulation, bimanual manipulation is more challenging as it requires different kinds of
coordination and orchestration of the two arms.
For the implementation side this makes it much more complex since synchronization is required when
controlling both arms at the same time.
The following table classifies the tasks according to the bimanual taxonomy of Krebs et al..
Here, key distinguishing factors are the coupling as well as the required coordination between the two
arms. We extended the classification in that we also distinguish between physical coupling, i.e., if one
arm exerts a force that could be measured by the other arm.
| Task | Coupled | Coordination | |||
|---|---|---|---|---|---|
| temporal | spatial | physical | symmetric | synchronous | |
| (a) push box | ✔ | ✔ | ✘ | ✔ | ✔ |
| (b) lift a ball | ✔ | ✔ | ✔ | ✔ | ✔ |
| (c) push two buttons | ✔ | ✘ | ✘ | ✔ | ✘ |
| (d) pick up a plate | ✔ | ✔ | ✔ | ✘ | ✘ |
| (e) put item in drawer | ✔ | ✘ | ✘ | ✘ | ✘ |
| (f) put bottle in fridge | ✔ | ✘ | ✘ | ✘ | ✘ |
| (g) handover an item | ✔ | ✔ | ✔ | ✘ | ✔ |
| (h) pick up notebook | ✔ | ✔ | ✔ | ✘ | ✘ |
| (i) straighten rope | ✔ | ✔ | ✔ | ✘ | ✔ |
| (j) sweep dust pan | ✔ | ✔ | ✔ | ✘ | ✘ |
| (k) lift tray | ✔ | ✔ | ✔ | ✔ | ✔ |
| (l) handover item (easy) | ✔ | ✔ | ✔ | ✘ | ✘ |
| (m) take tray out of oven | ✔ | ✔ | ✔ | ✘ | ✘ |
PerAct2
A Perceiver-Actor Framework for Bimanual Robotic Manipulation Tasks
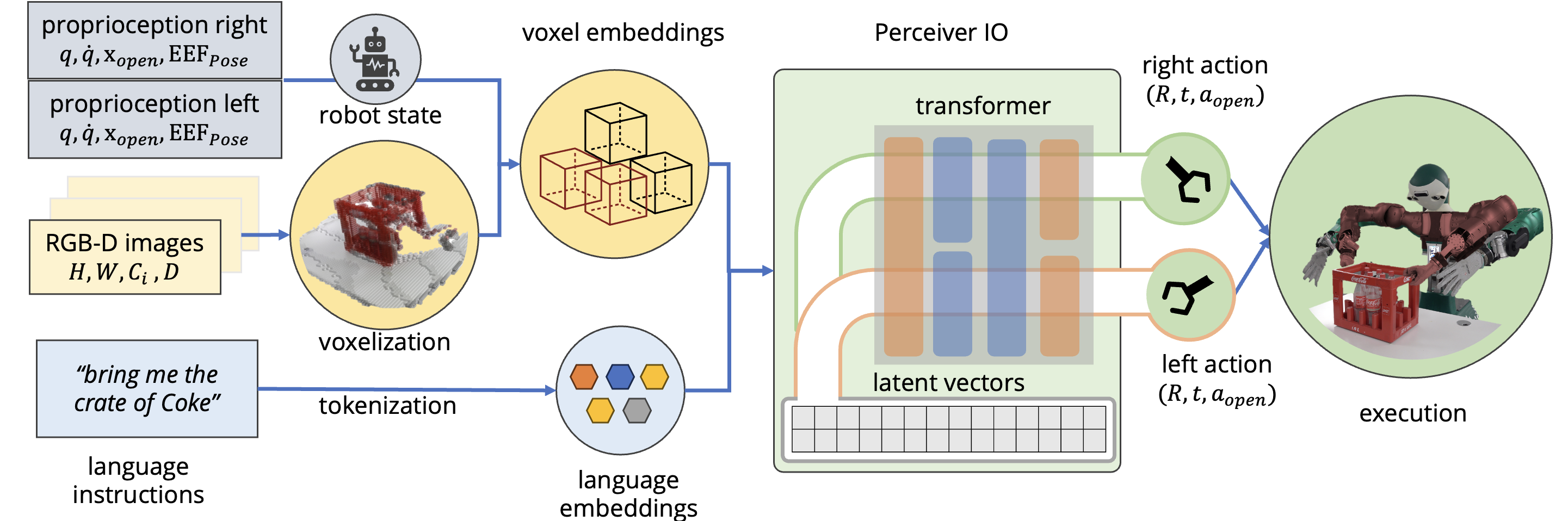
The system architecture. PerAct2 takes proprioception, RGB-D camera images as well as a task description as input. The voxel grid is constructed by merging data from multiple RGB-D cameras. A PerceiverIO transformer is utilized to learn features at both the voxel and language levels. The output for each robot arm includes a discretized action, which comprises a six-dimensional end-effector pose, the state of the gripper, and an extra indicator for planning motion with collision awareness.
Results
Real-world experiments
Simulation Results
Single task results
Method| Method | (a) box | (b) ball | (c) buttons | (d) plate | (e) drawer | (f) fridge | (g) handover |
|---|---|---|---|---|---|---|---|
| ACT | 0% | 36% | 4% | 0% | 13% | 0% | 0% |
| RVT-LF | 52% | 17% | 39% | 3% | 10% | 0% | 0% |
| PerAct-LF | ⭐ 57% | 40% | 10% | 2% | ⭐ 27% | 0% | 0% |
| PerAct2 (ours) | 6% | ⭐ 50% | ⭐ 47% | ⭐ 4% | 10% | ⭐ 3% | ⭐ 11% |
| Method | (h) laptop | (i) rope | (j) dust | (k) tray | (l) handover easy | (m) oven | |
| ACT | 0% | 16% | 0% | 6% | 0% | 2% | |
| RVT-LF | 3% | 3% | 0% | 6% | 0% | 3% | |
| PerAct-LF | 11% | 21% | ⭐ 28% | ⭐ 14% | 9% | 8% | |
| PerAct2 (ours) | ⭐ 12% | ⭐ 24% | 0% | 1% | ⭐ 41% | ⭐ 9% |